Solve graph problems with Breadth First Search (BFS) and Depth First Search (DFS) algorithms - JavaScript version

Search for a command to run...
No comments yet. Be the first to comment.
Concurrency and Parallelism in Golang

Patterns are everywhere This great comic is from False Knees and it illustrates that you can find patterns everywhere, you can also check out this National Graphic article. Your code base is no different. The objective of this article is to understa...

organize your containers with Docker Compose and use CURL to make requests

It's alive BUT There are huge codebases of RoR from famous companies such as Github, Gitlab, Airbnb, Shopify, Groupon and even Twitch that are still using it. However the ecosystem is definitely in decline and companies are struggling to recruit seni...


There's an xkcd for everything!
If you are preparing for interviews or just studying DSA you will eventually reach graph problems and then dynamic programming. This post is the step before recursion, we are going to see how BFS and DFS algorithms work iteratively with examples in JavaScript since most people have touched it in one way or another.
Note that if this is the first time you hear about BFS and DFS I'd recommend you go through binary trees first before starting with graphs.
To understand how these algorithms work first we need to have a proper understanding of stack and queue data structures.
I will be using examples from Programiz to illustrate some of my points. I'd recommend you check their content if this post isn't clear enough. Structy is another great page with plenty of free resources to get started.
Stack follows the LIFO principle: Last In First Out. You can think of it as a pile of plates (or anything you have to stack), every new item you put on top of others, or better put: every new item is put on the previous item and in order to get the last item you just take it from the pile. However, only the last item is available to take out.
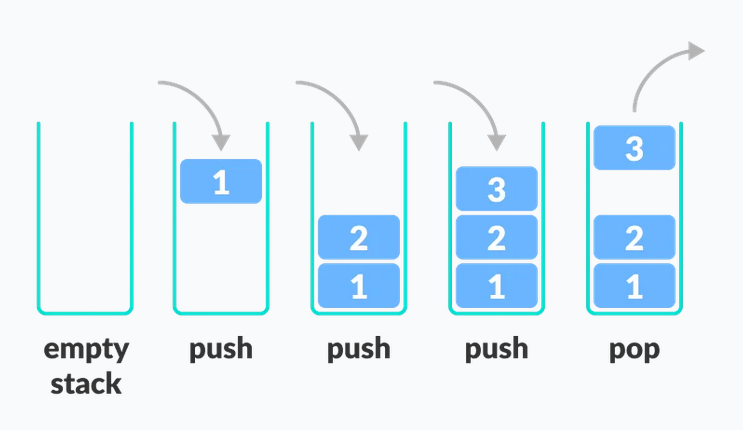
In this illustration from Programiz you can see that you keep pushing elements/items in the stack and you keep pushing new elements on top of each other and if you want to retrieve them then you need to retrieve the elements starting from the Last In because it's the First Out.
If you are not doing OOP or you need to implement the data structure itself a simple JavaScript use would be to just make an array:
const stack = []
//push element
stack.push(1)
//get last element
const lastElement = stack.pop()
Additionally stack usually has a method/function that allows you to peek at the last element:
//peek
const getLast = stack[stack.length-1]
Queue follows the FIFO principle: First In First Out. It follows the same principle as any queue, you get in line and wait until it's your turn, so if there are 5 people ahead of you and you are the number 6 then you need to wait for those 5 people to get in before you can go.
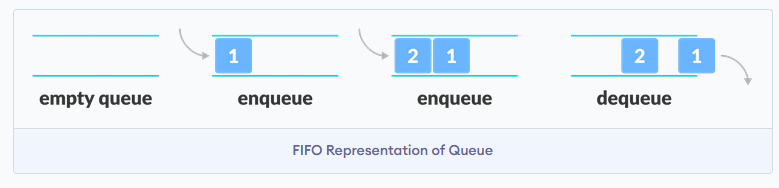
In this illustration from Programiz you can see two elements that get queued, the first to get in line (queue) is the first to get out.
The JavaScript implementation would be something like this:
const queue = []
//queue elements
queue.push(1) //queue: [1]
queue.push(2) //queue: [1,2]
queue.push(3) //queue: [1,2,3]
//dequeue elements
const firstEle = queue.shift() //this gets 1 and queue: [2,3]
const secondEle = queue.shift() //this gets 2nd and queue: [3]
const lastEle = queue.shift() //gets 3rd and queue: []
The main difference between stack and queue is that we don't pop any elements from the queue, the pop method/function will give us the last element but since we are working with queues we want to get the First In element which will go First Out.
You could also implement a queue in reverse order:
const queue = []
//queue elements
queue.unshift(1)
queue.unshift(2)
queue.unshift(3)
//dequeue elements
const first = queue.pop()
const second = queue.pop()
const third = queue.pop()
This is still a queue, the only difference is that we are inserting from the beginning (bottom) and popping the elements from the end (top).
Just a quick pause to remind you that if you use any methods/functions that have to move all array elements (unshift for example) this becomes an additional cost on your algorithm since moving all elements it's O(n) so generally speaking, if you have to choose you might want to try the stack data structure first since your elements inside of the array don't have to move.

When you are working with graphs the data/input for your function might be all over the place so you will need to organize it better or make it into something where you can easily apply the algorithms and data structures you are familiar with.
Before attempting to solve the problem you might want to first take a look at the data or input you are provided, and depending on what you need to do perhaps you should transform that data into something else, be it to avoid exponential runtime or just to see the problem better.
Just check if you might need a set, a hashmap or something else. With graph problems what we usually need is an adjacent matrix.
So for example, if we are given this LeetCode problem (1971. Find if Path Exists in Graph) where the input is as follows:
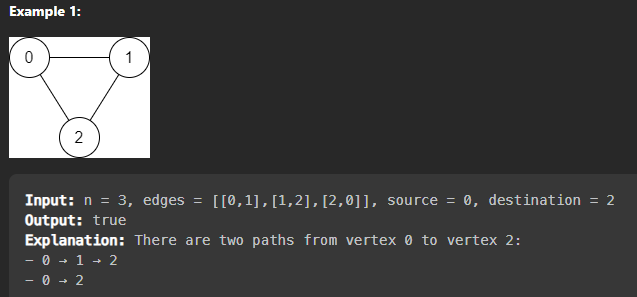
edges = [[0,1],[1,2],[2,0]]
We need to use a function to transform that array of edges into a matrix (I usually just call it getGraph since we want to get the graph from the array):
const getGraph = (edges) => {
const graph = {}
for(let i = 0; i < edges.length; i++){
let [a, b] = edges[i]
if(!graph[a]) graph[a] = []
if(!graph[b]) graph[b] = []
graph[a].push(b)
graph[b].push(a)
}
console.log(graph)
return graph
}
If you run that function you should get this output which corresponds to the picture of the graph above:
{ '0': [ 1, 2 ], '1': [ 0, 2 ], '2': [ 1, 0 ] }
In order to understand how BFS and DFS work one of the keys is to realise that we need to visit all the adjacent nodes of your current node, aka the neighbours. It might sound obvious and simple but you can miss it.
We will use a stack or a queue to keep track of our current node and then push the neighbour nodes into our stack or queue. The most important concept here is that we are working on our current node, aka the node which we took off from our stack or queue. This will make sense in a bit.
And why do we care about the neighbours so much? To avoid running over the same nodes, what is the best data structure if we want to think about unique values? A set! You get to store unique values and then check very fast if you already interacted with a value/element/node before.
In JavaScript if you want to make a set you do:
//name our set visited because we will track our visited nodes here
const visited = new Set()
Now that we have our set if we are interacting over our current node to check the neighbours we just do a for loop:
for(let neighbour of graph[currentNode]){
//check if our Set contains an adjacent node which means we already visited it
if(!visited.has(neighbour) //do something
}
This would be the same loop:
for(let neighbourIndex = 0; neighbour < graph[currentNode].length; neighbour++){
if(!visited.has(graph[neighbourIndex]) //do something
}
Now that we have the basic concepts down it should be easier to understand the implementation of both DFS and BFS. However, first I'd recommend you look up videos of what the algorithm does (without looking at the code). Here's a video from FreeCodeCamp and the creator of Structy, you don't have to look at the entire video just until you understand how DFS and BFS work visually:
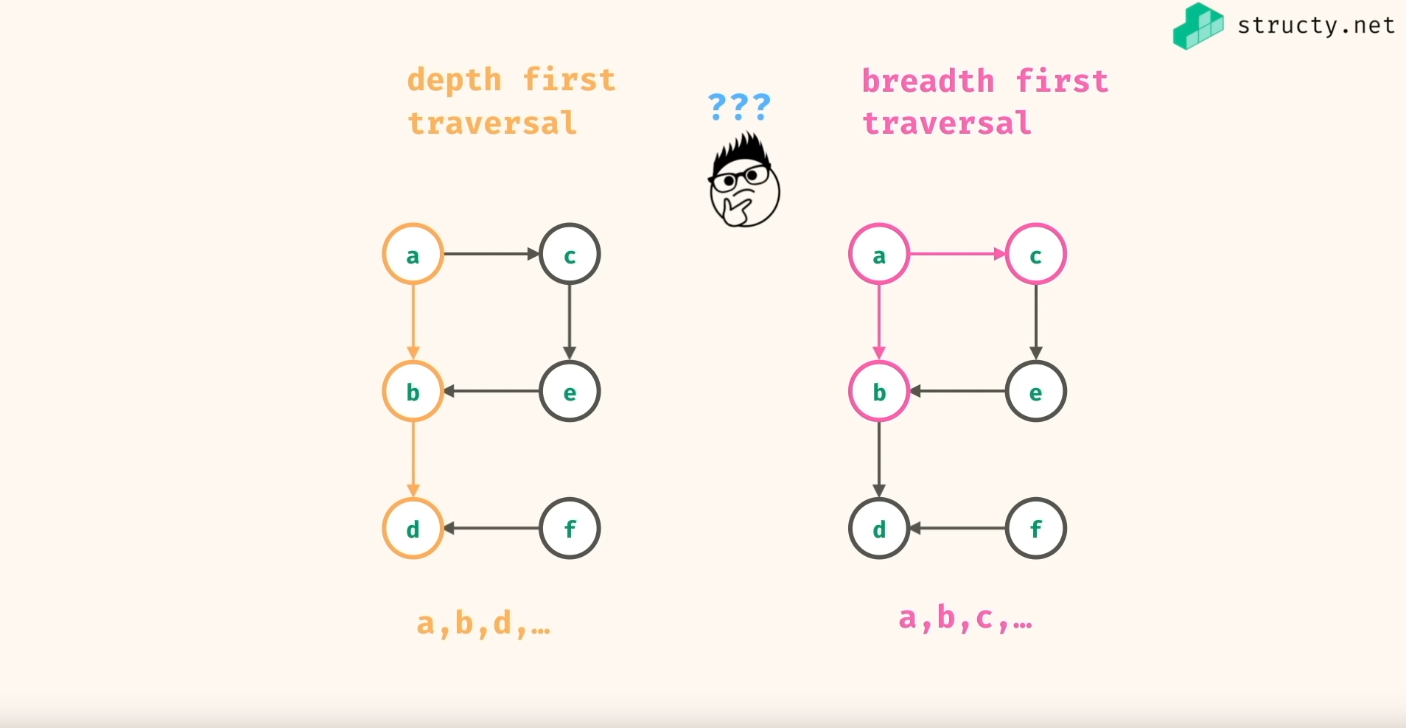
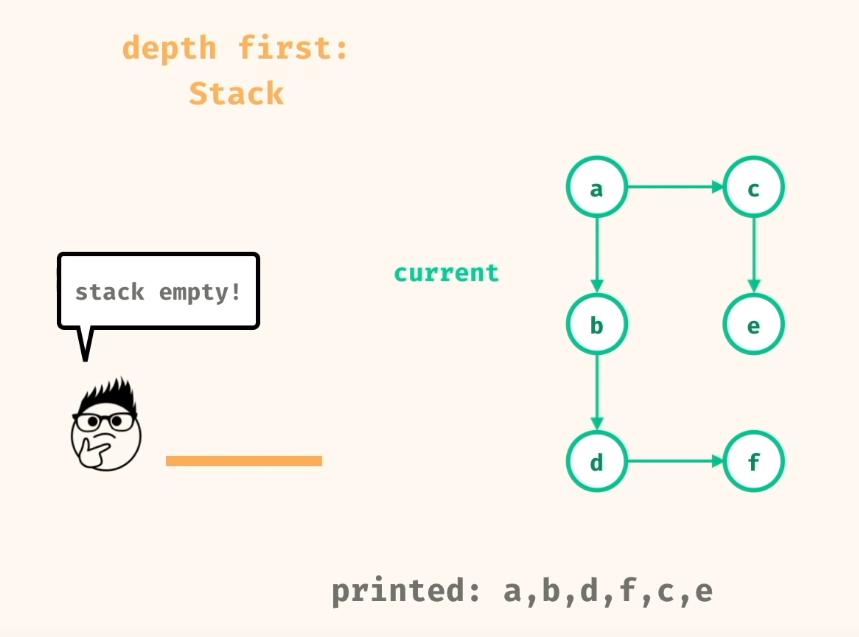
The best way to understand how DFS works is to think about its name, we are going to search in-depth first. This means that we will take our search in a specific direction until we hit a wall (or a null). If we were talking about trees DFS would just always go to the left or right node first, so basically we are just going to always go deep into one direction until we can't find anything.
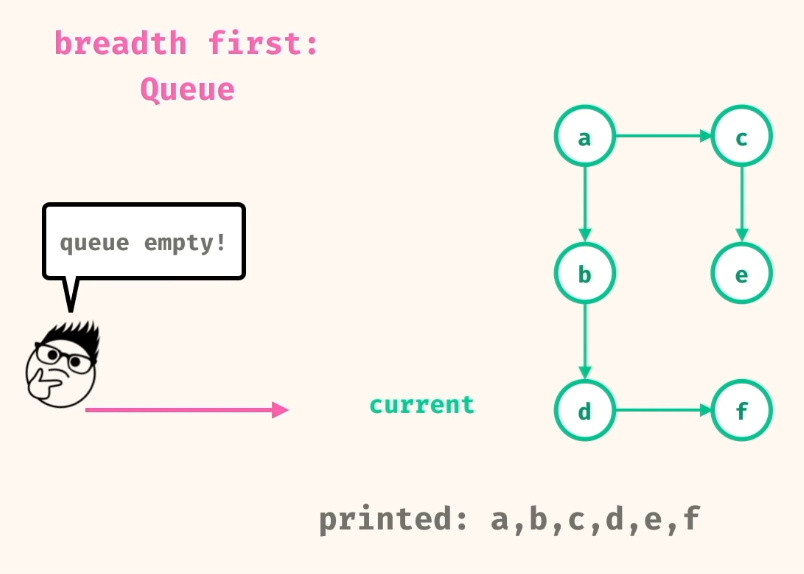
On the other hand, if we are using BFS then before going in deeper we will look around us and check for any adjacent nodes and if they exist then we will visit those first. So instead of going deeper in one direction as with DFS here, we'd go more in a circular manner to find the neighbours first before committing to a specific direction.
I can't recommend this video enough to understand the core concepts. You can also visit the Structy page directly.
Remember the previous LeetCode problem: (1971. Find if Path Exists in Graph)? We will solve it using DFS and everything we have learned so far.
Let's write a DFS algorithm to find a solution and check if a path exists between two nodes. I've included a lot of console.logs so you can see what's happening and how the algorithm is working, you can run it and check the different test cases for it.
I recommend that you edit the test cases and just go step by step, the most important part here is to understand how we are using the stack data structure and adding all the neighbours.
/**
* @param {number} n
* @param {number[][]} edges
* @param {number} source
* @param {number} destination
* @return {boolean}
*/
var validPath = function(n, edges, source, destination) {
const adj = getGraph(edges)
console.log(adj)
return hasPath(adj, source, destination)
};
const getGraph = (edges) => {
console.log('inside getGraph')
const graph = {}
for(let i = 0; i < edges.length; i++){
let [a, b] = edges[i]
if(!graph[a]) graph[a] = []
if(!graph[b]) graph[b] = []
graph[a].push(b)
graph[b].push(a)
}
console.log(graph)
return graph
}
const hasPath = (graph, src, dst) => {
console.log('inside haspath')
let visited = new Set()
let stack = [src]
while(stack.length > 0){
let curr = stack.pop()
if(curr === dst) return true
visited.add(curr)
console.log(visited)
console.log('stack: ')
console.log(stack)
console.log('curr:')
console.log(curr)
console.log('graph curr')
console.log(graph[curr])
for(let n of graph[curr]){
console.log(n)
if(!visited.has(n))stack.push(n)
}
}
return false
}
I recommend you go through the results on the console, in case you can't here's the console output for test case 2:
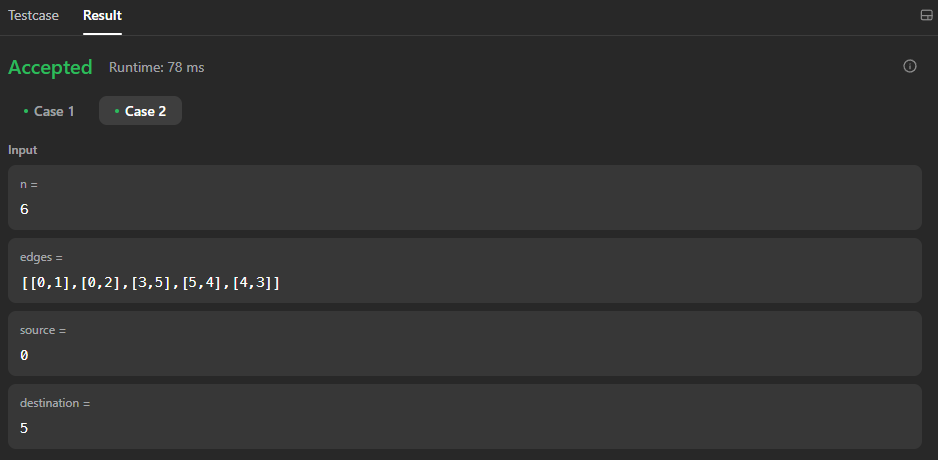
inside getGraph
{
'0': [ 1, 2 ],
'1': [ 0 ],
'2': [ 0 ],
'3': [ 5, 4 ],
'4': [ 5, 3 ],
'5': [ 3, 4 ]
}
{
'0': [ 1, 2 ],
'1': [ 0 ],
'2': [ 0 ],
'3': [ 5, 4 ],
'4': [ 5, 3 ],
'5': [ 3, 4 ]
}
inside haspath
Set(1) { 0 }
stack:
[]
curr:
0
graph curr
[ 1, 2 ]
1
2
Set(2) { 0, 2 }
stack:
[ 1 ]
curr:
2
graph curr
[ 0 ]
0
Set(3) { 0, 2, 1 }
stack:
[]
curr:
1
graph curr
[ 0 ]
0
Here's the function without all the clutter and more comments, it's used to determine if a path exists between a source and destination node.
const hasPath = (graph, src, dst) => {
//init set to check if we have been here already
let visited = new Set()
//put the source node in our stack since we are starting here
let stack = [src]
//as long as the stack isn't empty it means we are still checking nodes
while(stack.length > 0){
//we get our current node from the stack
let curr = stack.pop()
//check if the current node is our destination
if(curr === dst) return true
//since we already visited this node we add it to our set of visited nodes
visited.add(curr)
//if we didn't visit the neighbours of our current node then add them to the stack
//where we check if the current node is the destination
for(let n of graph[curr]){
if(!visited.has(n)) stack.push(n)
}
}
//if we can't find the destination then return false
return false
}
function doSomething(a,b,c) {
}
is the same as
const doSomething = (a,b,c) => {
}
The main difference between DFS and BFS is how we get our current node (and therefore the way we store and iterate over the neighbours). With a stack you will always go in the same direction until the end of the graph while with a queue you will visit the nodes that are on the same "level" first.
Here's the modification of our current DFS algorithm into BFS:
const hasPath = (graph, src, dst) => {
//init set to check if we have been here already
let visited = new Set()
//init queue with the source node in
let queue = [src]
//as long as the stack isn't empty it means we are still checking nodes
while(queue.length > 0){
//we get our current node from the queue
let curr = queue.shift()
//check if the current node is our destination
if(curr === dst) return true
//since we already visited this node we add it to our set of visited nodes
visited.add(curr)
//if we didn't visit the neighbours of our current node then add them to the queue
//where we check if the current node is the destination
for(let n of graph[curr]){
if(!visited.has(n)) queue.push(n)
}
}
//if we can't find the destination then return false
return false
}
Note that if we try to run it we will pass almost all the test cases except the ones with a large input, this is due to BFS being more costly since it's using a queue instead of a stack.
A common case for BFS use in graph problems is to find the shortest path from one node to another, you could use something like this BFS helper function to get the distance:
const bfsHelper = (graph, node, target, visited) => {
//define queue which will store our current node and the distance count
let queue = [[node, 0]]
//iterate until we don't have any current nodes left
while(queue.length > 0){
//extract the current nude and current distance
let [curr, distance] = queue.shift()
//if our current node equals target then we are done with our algorithm and we return how many steps we had to take to find it
if(curr === target) return distance
//if the current node isn't our target then we add the current node to a visited set
visited.add(curr)
//iterate over our adjacent neighbours to add them to the queue if we haven't visited them yet
for(let neighbor of graph[curr]) {
if(!visited.has(neighbor)) {
queue.push([neighbor, distance+1])
}
}
}
//if we can't find the target then we return -1
return -1
}
The objective of this post was to establish some key concepts and see how DFS and BFS behave as well as approach the graph problems, the next steps would be to dive into recursion or perhaps go back to binary tree problems.
It might take a while to understand the best approaches or how things work, just keep practising and it will click eventually. And if you are tired of LeetCode or HackerRank I highly recommend CodeWars.